Model Parameters
To customize model settings for a conversation:
- In any Threads, click Model tab in the right sidebar
- You can customize the following parameter types:
- Inference Parameters: Control how the model generates responses
- Model Parameters: Define the model's core properties and capabilities
- Engine Parameters: Configure how the model runs on your hardware
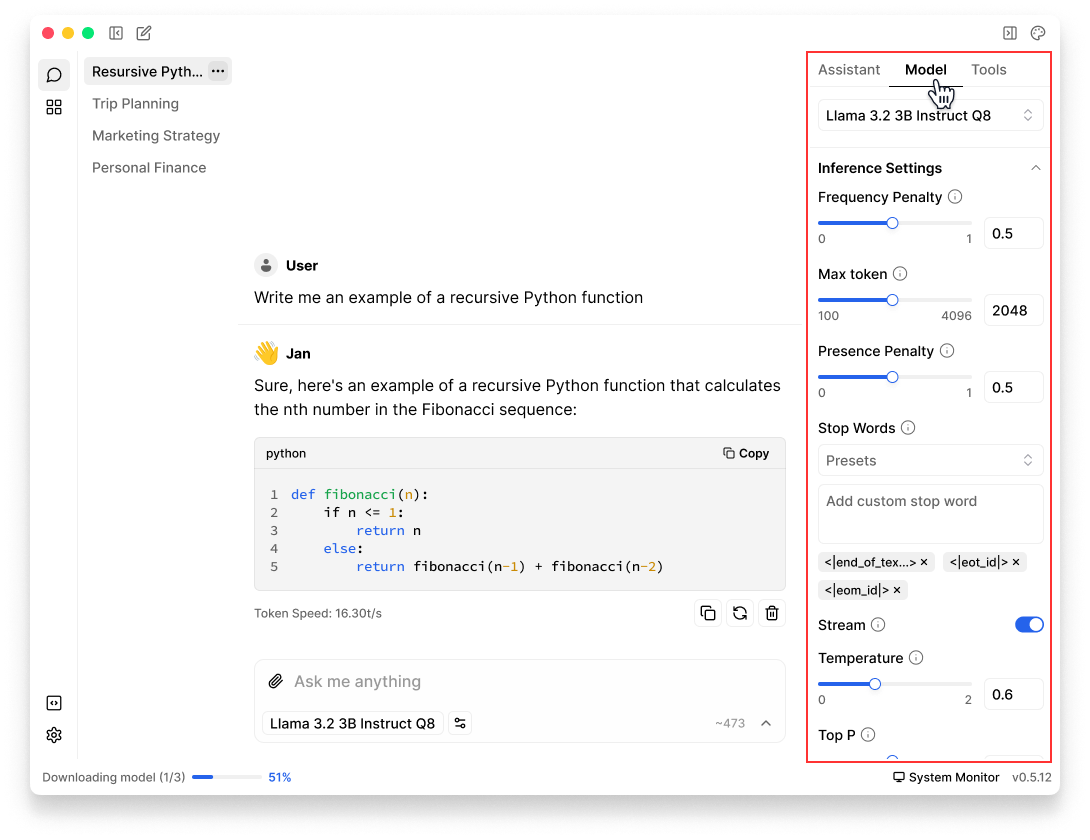
Inference Parameters
These settings determine how the model generates and formats its outputs.
| Parameter | Description |
|---|---|
| Temperature | - Controls response randomness. - Lower values (0.0-0.5) give focused, deterministic outputs. Higher values (0.8-2.0) produce more creative, varied responses. |
| Top P | - Sets the cumulative probability threshold for token selection. - Lower values (0.1-0.7) make responses more focused and conservative. Higher values (0.8-1.0) allow more diverse word choices. |
| Stream | - Enables real-time response streaming. |
| Max Tokens | - Limits the length of the model's response. - A higher limit benefits detailed and complex responses, while a lower limit helps maintain conciseness. |
| Stop Sequences | - Defines tokens or phrases that will end the model's response. - Use common concluding phrases or tokens specific to your application’s domain to ensure outputs terminate appropriately. |
| Frequency Penalty | - Reduces word repetition. - Higher values (0.5-2.0) encourage more varied language. Useful for creative writing and content generation. |
| Presence Penalty | - Encourages the model to explore new topics. - Higher values (0.5-2.0) help prevent the model from fixating on already-discussed subjects. |
Model Parameters
This setting defines and configures the model's behavior.
| Parameter | Description |
|---|---|
| Prompt Template | A structured format that guides how the model should respond. Contains placeholders and instructions that help shape the model's output in a consistent way. |
Engine Parameters
These settings parameters control how the model runs on your hardware.
| Parameter | Description |
|---|---|
| Number of GPU Layers (ngl) | - Controls how many layers of the model run on your GPU. - More layers on GPU generally means faster processing, but requires more GPU memory. |
| Context Length | - Controls how much text the model can consider at once. - Longer context allows the model to handle more input but uses more memory and runs slower. - The maximum context length varies with the model used. |
By default, Jan defaults to the minimum between 8192 and the model's maximum context length, you can adjust this based on your needs.